



一、均数的抽样误差与标准误
前面讲过,医学研究绝大部分是从总体中随机抽取样本进行研究,然后通过样本信息去推论总体特征。这样就会存在抽样误差。抽样误差是抽样研究中产生的样本统计量与总体参数之间的差异,或不同的样本统计量之间的差异。例如,抽取某地2015年100名健康女大学生身高的资料得到身高的均数为161.5 cm,该样本均数不一定等于该地健康女大学生身高的总体均数,如果再抽取100名得到的身高的均数也不一定恰好等于161.5 cm。这种由于抽样引起的样本均数与总体均数或样本均数与样本均数之间的差异叫做均数的抽样误差。
由于个体差异的存在,抽样误差是永恒存在的,但其大小可以评估,其分布具有规律性。
均数的标准误是描述均数抽样误差大小的指标,简称标准误,其计算公式为

式中σx为标准误的理论值。在实际工作中由于总体标准差σ往往是未知的,只能得到样本标准差s,用s代替σ可求得标准误的估计值sx,即

标准误实际上是样本均数的标准差,它除了反映均数抽样误差大小外,也反映了样本均数之间的离散程度。
[例7.14]某地2015年100名健康女大学生身高均数为161.5 cm,标准差为4.6 cm,求其标准误。
把相应数据代入公式(722)中,计算得到标准误为
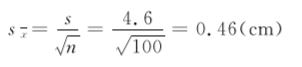
标准误与标准差是常用的两种统计指标,此二者既有共同点也有显著的区别。两者均为变异指标,标准差表示个体变量值之间的离散程度,而标准误则表示样本均数间的离散程度;标准差小表示变量值之间的离散程度小,反映样本均数对各变量值的代表性好;标准误小表示抽样误差小,反映样本均数对总体均数的代表性好;标准差结合均数可估计参考值范围;标准误结合均数用于估计总体均数的可信区间。
二、t分布
(一) t分布的概念
前面讲过,为了应用方便,可对正态变量x采用u=x-μσ变换,将一般的正态分布N(μ,σ2)变换为标准正态分布N(0,1)。若从正态总体中随机抽取样本含量相等的多个样本,这些样本均数x服从正态分布N(μ,σ2x),那么就可以对正态变量x进行u变换:
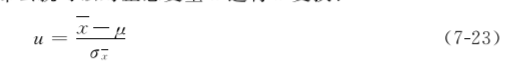
变换为标准正态分布N(0,1),即u分布。实际工作中σx往往是用sx来估计,为了区别,这时对正态变量x采用的不是u变换而是t变换,即

从均数为μ,标准差为σ的正态总体中随机抽取样本含量为n的样本,计算出样本均数x与其标准误sx,如果总体均数已知,那么每个样本可按公式(724)计算出相应的t值,则这些t值的分布称为t分布。
(二) t分布的特征
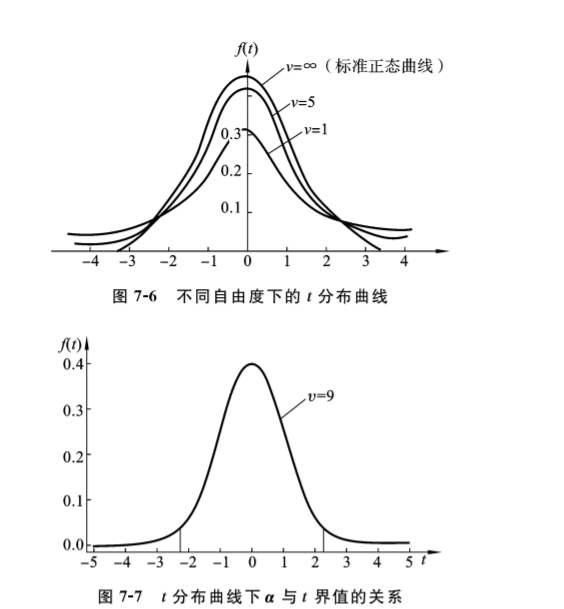
t分布曲线与u分布曲线虽都为对称于0的倒钟形曲线,但也有以下几点差异。①t分布曲线是一簇对称于0的曲线,u分布曲线只有1条;②u分布曲线是标准正态峰,t分布曲线在自由度较小时,曲线峰的高度低于标准正态曲线,尾部面积大于标准正态曲线尾部面积(翘尾低狭峰)。随着自由度增大,t分布曲线逐渐逼近标准正态曲线,当自由度为无穷大时,t分布曲线和标准正态曲线完全吻合,如图7-6所示。
在自由度确定后,t分布曲线下双侧尾部面积P或单侧尾部面积P指定α时,横轴上相应的t界值,记作tα,υ。同标准正态分布曲线一样,统计应用中最关心的是t分布曲线下的面积与横轴t值间的关系。为了使用方便,统计学家已编了不同自由度υ下的t界值表(附录D)。t分布曲线下α与t界值的关系如图7-7所示。
如当υ=9,单侧尾部面积(即概率)α=0.05时,由表中查得单尾t0.05,9=1.833,也就是说按t分布的规律,理论上有P(t≤-1.833)=0.05或P(t≥1.833)=0.05。或者表示为
单尾:P(t≤-tα,υ)=α或P(t≥tα,υ)=α
双尾:P(t≤-tα/2,υ)+P(t≥tα/2,υ)=α
即P(-tα/2,υ<t<tα/2,υ)=1-α。
t分布的由来
三、总体均数的估计
实际工作中,我们往往希望从样本指标推断总体指标,这种方法称为参数估计,例如,从样本均数估计总体均数的大小。参数估计的方法有点估计和区间估计两种。下面以总体均数的估计为例进行讲解。
(一) 点估计(point estimation)
点估计就是以得到的样本均数估计总体均数,这种估计方法简单易行,但未考虑抽样误差,不同的样本会得到不同的均数,很难评价其估计的正确程度。
(二) 区间估计(interval estimation)
按一定概率估计总体均数所在范围,得到的范围称可信区间(confidence interval,简记为CI),这种估计总体均数的方法称为区间估计。也就是说,随机抽取样本后,在考虑抽样误差存在时,用样本均数估计总体均数的可能范围。统计学上通常用95%和99%的概率估计总体均数所在范围,也称之为95%可信区间(简记为95%CI)和99%可信区间(简记为99%CI)。计算公式如下。
1. u分布规律估计 当n足够大(n≥50)时,t分布与u分布接近,可用u分布规律估计总体均数μ的区间

[例7.15]已知某地2015年100名健康女大学生x=161.5 cm,s=4.6 cm,试估计该地健康女大学生身高总体均数95%可信区间。
本例由于n=100,x=161.5 cm,s=4.6 cm,sx=4.6/100。按公式(725)计算得到(161.5-1.96×4.6/100,161.5+1.96×4.6/100)=(160.6 cm,162.4 cm)
该地健康女大学生身高总体均数95%可信区间为160.6~162.4 cm。
这里160.6 cm称为可信区间的下限,162.4 cm为可信区间的上限,简称为可信限(confidence limit,简记为CL),它们是两个限值。可信区间是以上、下可信限为界限的范围。
2. t分布规律估计 当n<50时,用t分布规律估计总体均数μ的区间,结果为

式中,t0.05,υ与t0.01,υ是按双侧P值为0.05与0.01,自由度υ=n-1时对应的t界值。
[例7.16]随机抽取某地6名9岁健康男童体重资料,测得该样本的体重均数为32.46 kg,标准差为2.61 kg,问该地健康男童体重均数的95%可信区间是多少?
本例υ=n-1=5,α=0.05查附录D得t0.05,5=2.571,按式(727)计算得到
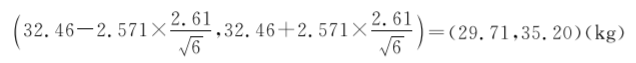
该地9岁健康男童体重总体均数95%的可信区间为29.71~35.20 kg。
由上可知可信区间的含义,以总体均数的95%可信区间为例:在100次随机抽样所得到的100个可信区间中,理论上有95个可信区间包括总体均数(估计正确的可能性是95%)。
可信区间的优劣取决于两个因素:一是可信度,即该区间包括总体均数的概率大小,可信度越大越好,也就是99%的可信度比95%的可信度好;二是区间的宽度,也就是精确度。当然是宽度越窄精确度越高。在样本含量确定的情况下,两者是相互矛盾的。故不能笼统地认为99%的可信区间比95%的可信区间好。一般情况下,95%的可信区间更常用。在可信度一定的情况下,适当增加样本含量可以减少区间的宽度。
四、假设检验的基本思想与步骤
(一) 假设检验的基本思想
假设检验(hypothesis testing)又称显著性检验,是统计推断的另一重要内容,是用来判断样本与总体的差异是由抽样误差引起的还是由本质差别造成的。现以例[7.17]为例说明假设检验的基本原理和步骤。
[例7.17]根据大量调查得知,健康成年男子脉搏均数是72次/分。某医生在某山区随机调查了25名健康成年男子,其脉搏均数为74.2次/分,标准差为6.5次/分。能否认为该山区成年男子脉搏数与一般健康成年男子的脉搏数不同?
在实际工作中遇到两均数间不相等时,要考虑两种可能:①两者来自同一总体,差别是由抽样误差所致;②两者来自不同总体,差别是由本质差别所致(本例由于环境条件的影响,导致山区成年男子脉搏数高于一般)。如何作出判断?统计学是通过假设检验来回答这个问题的。
假设检验的基本思路是:根据研究目的对总体特征提出假设,然后再利用样本信息去验证先前提出的假设是否成立。如果样本数据不支持原假设,则在一定的概率条件下,应拒绝该假设;相反,如果样本数据不能够充分证明原假设不成立,则不能推翻假设成立的合理性和真实性。假设检验推断过程所依据的基本思想是小概率原理和反证法思想。
(二) 假设检验的一般步骤
下面以[例7.17]为例介绍假设检验的基本步骤。
1. 建立假设 假设有两种:一是无效假设(null hypothesis),也称检验假设、原假设或零假设,用H0表示,假设两总体均数相等(μ=μ0),即样本均数x所代表的总体均数μ与已知的总体均数μ0相等。x和μ0差别仅仅由抽样误差所致;二是备择假设(alternative hypothesis),用H1表示,假设两总体均数不相等(μ≠μ0),即样本均数x所代表的总体均数μ与已知的总体均数μ0不相等。x和μ0差别由本质差别所致;二者都是根据统计推断的目的提出的对总体特征的假设,是相互联系且对立的假设。
建立假设前,先要根据分析目的和专业知识明确双侧检验还是单侧检验。若目的是推断两总体是否不等(即是否μ≠μ0),并不关心μ>μ0还是μ<μ0,应用双侧检验;若从专业知识已知不会出现μ>μ0或不会出现μ<μ0,则用单侧检验。本例中,山区成年男子的脉搏高于或低于一般成年男子脉搏的两种可能性都存在,则用双侧检验;若根据专业知识,认为山区成年男子脉搏不会低于一般,则用单侧检验。一般认为双侧检验较为稳妥,故较常用。
2. 确定检验水准 检验水准(size of a test)又称显著性水准(significance level),符号为α,是指本次假设检验设定的小概率事件的概率标准。α常取0.05或0.01,也可根据不同研究目的给予不同设置。
3. 选定检验方法和计算统计量 根据分析目的、设计类型和资料类型选用适当的检验方法,计算相应的统计量。如配对设计的两样本均数比较,选用配对t检验;完全随机设计的两样本均数比较,选用u检验(大样本时)或t检验(小样本时)等。不同的检验方法计算公式不同。
4. 确定P值 P值是指在由H0所规定的总体中随机抽样,获得等于及大于(或等于及小于)现有统计量的概率。用求得的样本统计量查相应的界值表,确定P值。
5. 作出推断结论 将获得的概率P值与检验水准比较作出拒绝或不拒绝H0的统计结论。若P≤α,则结论为按照所取的检验水准,拒绝H0,接受H1,差异具有统计学意义;若P>α,则结论为按照所取的检验水准,不能拒绝H0,差异无统计学意义。
五、均数的t检验和u检验
t检验和u检验可用于两均数的比较。t检验是指根据t分布规律对H0假设进行检验,u检验是指根据u分布规律对H0假设进行检验。当样本含量较大(如n≥50)时,应用u检验;当样本含量较小(如n<50)时,应用t检验。t检验时要求样本来自正态分布总体,两小样本均数比较t检验时要求两总体方差相等。
(一) t检验
t检验的应用条件:①样本含量较小(如n<50);②样本来自正态总体;③在做两个样本均数比较时,还要求两样本相应的总体方差相等,称为方差齐性。
1. 单样本t检验(小样本均数与已知总体均数的比较)单样本t检验是已知样本均数(x)与已知总体均数的比较。样本均数代表的总体用μ表示,已知总体均数用μ0表示,一般是指理论值、标准值或者根据大量观察所得的稳定值。计算公式为
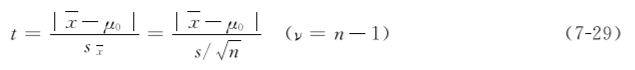
(1) 建立假设,确定检验水准。
H0:μ=μ0,即该山区健康成年男子脉搏均数与一般健康成年男子脉搏均数相同。
H1:μ≠μ0,即该山区健康成年男子脉搏均数与一般健康成年男子脉搏均数不同。
α=0.05。
(2) 计算检验统计量。
本例n=25,x=74.2次/分,s=6.5次/分,μ0=72次/分,代入公式(729)得到
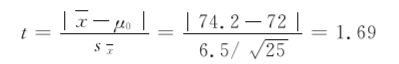
(3) 确定P值,做出推断结论。
本例自由度υ=25-1=24,查t界值表,得t0.05,24=2.064,因为1.69<2.064,所以P>0.05。按α=0.05的检验水准,P>α,不拒绝H0,差异无统计学意义,根据现有资料尚不能认为山区健康成年男子脉搏数与一般健康成年男子不同。
2. 配对样本t检验简称配对t检验,适用于配对设计的计量资料。配对设计主要有以下三种情形:①同一受试对象处理前后的数据比较;②同一受试对象两个部分分别接受不同处理或同一样品用两种方法(仪器等)检验的结果比较;③两种同质受试对象分别接受两种处理后的数据比较。解决这类问题首先要求出各对差值的均数(d)。理论上若两种处理无差别,则差值的总体均数μd应为0。因此,配对设计的均数比较可以看成样本均数d与总体均数μd(μd=0)的比较。计算公式为
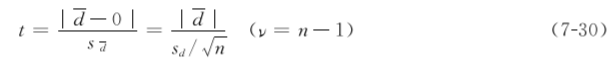
式中:d为每对数据的差值;d为差值的样本均数;sd为差值的标准差;sd为差值的标准误;n为对子数。
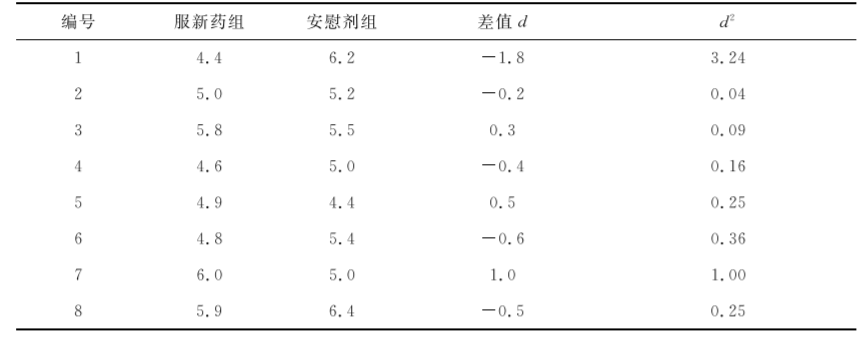
[例7.18]为研究一种新药对女性血清胆固醇含量是否有影响,可将20名同年龄女性配成10对。每对中随机抽取一人服用新药,另一人服用安慰剂,经一段时间后,测定血清胆固醇含量(mmol/L),结果见表79。问两组血清胆固醇含量有无差别(即新药对女性血清胆固醇含量是否有影响)?

(1) 建立假设,确定检验水准。
H0:μd=0,即新药对女性血清胆固醇含量无影响。
H1:μd≠0,即新药对女性血清胆固醇含量有影响。
α=0.05。
(2) 选择检验方法,计算统计量。
先计算差值d和d2,见表7-9。
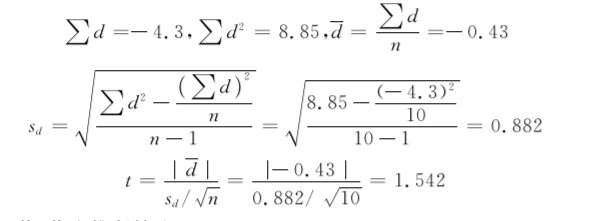
(3) 确定P值,作出推断结论。
本例自由度υ=n-1=9,查t界值,双侧t0.05,9=2.262;因为1.542<2.262,所以P>0.05。按α=0.05的检验水准,不拒绝H0,根据现有资料还不能认为服用该新药对女性血清胆固醇含量有影响。
[例7.19]某医生用药物治疗8例高血压患者,治疗前后舒张压测量数据见表710。问该药是否对高血压患者治疗前后舒张压有影响?
表7-10某药治疗高血压患者前后舒张压(mmHg)情况
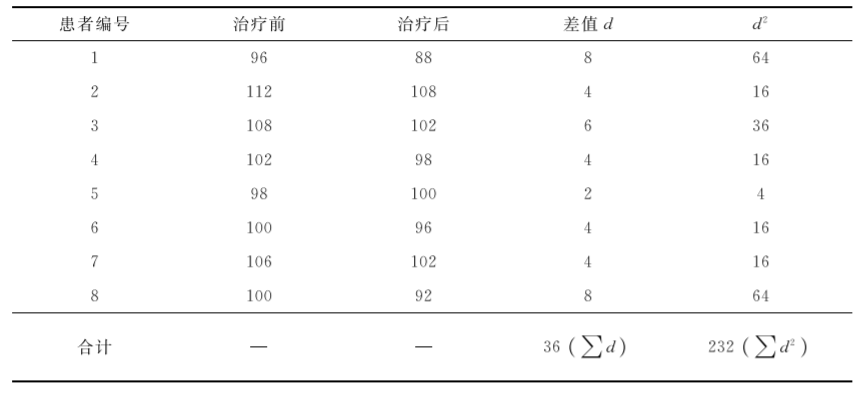
(1) 建立假设,确定检验水准。
H0:μd=0,即新药对高血压患者舒张无影响。
H1:μd≠0,即新药对高血压患者舒张无影响。
α=0.05。
(2) 选择检验方法,计算统计量。
将n=8,d=∑dn=368=4.50,sd=3.162,代入公式(730),得到
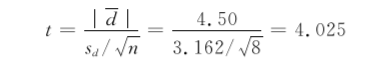
(3) 确定P值,作出推断结论。
本例自由度υ=n-1=7,查t界值表,双侧t0.05,7=2.365;因为4.025>2.365,所以P<0.05。按α=0.05的检验水准,拒绝H0,接受H1,差异有统计学意义,可以认为该药有降低舒张压的作用。
3. 两独立样本t检验(两小样本均数的比较) 两独立样本t检验,又称成组设计t检验,适用于完全随机设计的两样本均数的比较。目的是推断两组样本各自所属总体的总体均数μ1和μ2是否有差别。成组设计主要有两种情形:①分别从两个总体中随机抽取样本,观察某变量值;②将受试对象完全随机地分配到两个不同的处理组中去,观察某变量值。计算公式为

式中:n1和n2分别为两样本含量;x1和x2分别表示两样本均数;s2c为两样本的合并方差;自由度υ=n1+n2-2。其中
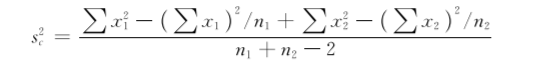
当两个样本标准差s1和s2已知时,则合并方差s2c为
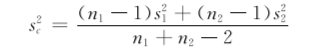
如果n1=n2,并已知s1和s2时,则
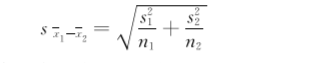
[例7.20]随机抽取20例糖尿病患者,随机分为2组,一组10人,甲组单纯用药物治疗,乙组用药物合并饮食治疗,2个月后测空腹血糖(mmol/L)如下。问甲、乙两组采用两种方法治疗糖尿病患者,其空腹血糖值是否相同?
甲组:8.4,10.5,12.0,13.9,11.2,16.8,18.0,15.7,16.6,15.6
乙组:5.4,6.4,7.1,8.1,6.7,12.0,11.2,8.6,7.4,6.5
检验步骤如下:
(1) 建立假设,确定检验水准。
H0:μ1=μ2,即甲、乙两组采用两种方法治疗糖尿病患者空腹血糖值相同。
H1:μ1≠μ2,即甲、乙两组采用两种方法治疗糖尿病患者空腹血糖值不同。(https://www.xing528.com)
α=0.05。
(2) 选择检验方法,计算统计量。
分别计算两组的均值和标准差:x1=13.87,s1=3.19;x2=7.94,s2=2.13。
代入公式(734),算得合并标准误为
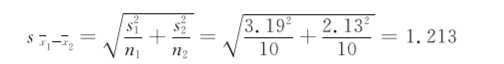
再代入公式(731),结果为
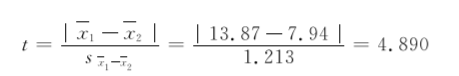
(3) 确定P值,做出推断结论。
本例自由度υ=n1+n2-2=10+10-2=18,查t界值,得双侧t0.05,18=2.101;因为4.890>2.101,所以P<0.05。按α=0.05的检验水准,拒绝H0,接受H1,差异有统计学意义,可以认为甲、乙两组采用两种方法治疗糖尿病患者空腹血糖值不同,甲组较高,乙组较低。
(二) u检验
当样本含量均较大(如n≥50)时,根据中心极限定理,即使总体分布偏离正态,其样本均数仍近似正态分布,故可用u检验。所应用的检验统计量u值的计算公式:
样本均数与已知总体均数比较的u检验:

两样本均数比较的u检验:
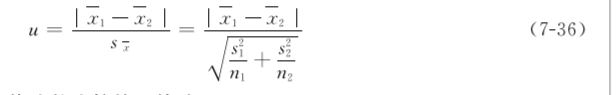
1. 大样本均数与已知总体均数比较的u检验
[例7.21]已知正常成年男子血红蛋白均值为140 g/L,今随机调查某工厂成年男子60人,测得其血红蛋白均值为125 g/L,标准差为15 g/L。问该厂成年男子血红蛋白均值与一般成年男子是否不同?
检验步骤如下。
(1) 建立假设,确定检验水准。
H0:μ=μ0,即该厂成年男子血红蛋白均值与一般成年男子相同。
H1:μ≠μ0,即该厂成年男子血红蛋白均值与一般成年男子不同。
α=0.05。
(2) 选择检验方法,计算统计量。
将n=60,x=125,s=15,μ0=140代入公式(735),得到
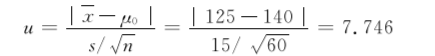
(3) 确定P值,作出推断结论。
因为7.746>1.96,所以P<0.05,按α=0.05的检验水准,拒绝H0,接受H1,差异有统计学意义,可以认为该厂成年男子血红蛋白均值与一般成年男子不同,该厂成年男子血红蛋白均值低于一般成年男子。
2. 成组设计的两个大样本均数比较的u检验
[例7.22]随机抽取某地市区男婴120名,出生体重均数为3.29 kg,标准差为0.44 kg;随机抽取该市郊区100名男婴,出生体重均数为3.23 kg,标准差为0.47 kg。问该地市区和郊区男婴出生体重均数是否相同?
(1) 建立假设,确定检验水准。
H0:μ1=μ2,即某地市区和郊区男婴出生体重均数相同。
H1:μ1≠μ2,即某地市区和郊区男婴出生体重均数不同。
α=0.05。
(2) 选择检验方法,计算统计量。
n1=120,n2=100,x1=3.29,x2=3.23,s1=0.44,s2=0.47代入公式(736)中,得到
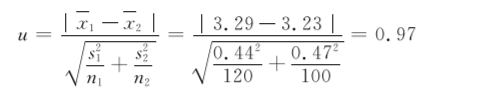
(3) 确定P值,做出推断结论。
因为0.97<1.96,所以P>0.05,按照α=0.05的检验水准,不拒绝H0,差异无统计学意义,尚不能认为该地市区和郊区男婴出生体重不同。
六、假设检验的注意事项
(一) 两类错误
假设检验所作的推断结论有可能产生两种错误。
(1) 第一类错误,即Ⅰ型错误,拒绝了实际上成立的H0,即弃真的错误。其概率大小即检验水准,用α表示。
(2) 第二类错误,即Ⅱ型错误,不拒绝实际上不成立的H0,即纳伪的错误。其概率大小用β表示,β的大小很难确切估计。
(二) 资料要有严密的设计
这是假设检验的前提。要从同质总体中随机抽取样本,保证组间均衡,具有可比性,即除了对比的因素(如实验用药和对照药)外,其他可能影响结果的因素(年龄、性别、病情轻重等)均应相同或相近。
(三) 不同的资料应选用不同的假设检验方法
应根据统计资料特点、设计方案、样本含量大小及研究目的等,选用符合适用条件的假设检验方法。例如配对资料要用配对t检验;两个样本均数比较时,小样本用t检验,大样本用u检验。两个小样本均数比较,要求样本来自正态总体,并且总体方差相等。
(四) 统计结论的正确表述
在做统计指标的假设检验时,如果检验结果有统计学意义,习惯上称为差别有显著性。它是指当随机抽样,由样本信息计算检验统计量,获得这样大或更大的统计量值的可能性很小,因而拒绝H0。这里回答是否接受或拒绝检验假设而不回答实际比较的样本所代表的总体指标差别有多大。因此有显著性不等于差别很大;反之,不拒绝H0,习惯上称为差异无显著性,但不应误解为相差不大。因此,应注意实际差别大小与统计意义的区别。
(五) 假设检验的结论不能绝对化
所有统计的假设检验都是概率,不管拒绝H0或不拒绝H0,都有可能发生推断错误,即两类错误。当计算出统计量的P值接近α时,应慎重下结论,可以增加观察例数,做进一步的研究。
(六) 正确选择单侧检验与双侧检验
在做假设检验时,应事先根据专业知识和问题的要求在设计时确定采用单侧检验还是双侧检验,不能在计算检验统计量后才主观确定。在做同一资料的检验时,有可能双侧检验无统计学意义而单侧有统计学意义。这是因为单侧检验比双侧检验更易得到差别有统计学意义的结论。因此,报告结论时,应列出所采用的是单侧检验还是双侧检验、检验方法、检验水准和P值的确切范围,然后结合专业做出专业结论。
小 结
1. 计量资料统计描述频数表编制分四步。频数分布类型有正态分布、偏态分布。频数分布特征有集中趋势和离散趋势。
描述计量资料集中趋势的指标有算术均数、几何均数、中位数。描述计量资料离散趋势的指标有全距、四分位数间距、方差、标准差、变异系数。
正态分布特征:一个高峰(均数所在处);以均数为中心左右对称;两个参数(位置参数和变异度参数);正态分布曲线下的面积有一定分布规律。
2. 计量资料统计推断包括参数估计和假设检验。参数估计分为点估计和区间估计。区间估计分为u分布法(大样本)和t分布法(小样本)。
假设检验时,小样本用t检验,大样本用u检验。t检验方法有三种:小样本均数与已知总体均数的比较;两个小样本均数的比较;配对t检验。u检验方法有两种:大样本均数与已知总体均数的比较;两个大样本均数的比较。注意公式的选择。
思 考 题
1. 对计量资料进行统计描述时,如何选择适宜的指标?
2. 为什么要进行标准正态变换?
3. 什么条件下要用配对t检验?
4. t检验和u检验有哪些区别?
5. 假设检验的注意事项有哪些?
自 测 题
一、A1型题(单项选择题)
1. 用均数和标准差可全面描述( )的分布特征。
A.正偏态资料 B.负偏态资料 C.正态分布和近似正态分布
D.任何分布 E.二项分布
2. 从一个数值变量资料的总体中抽样,产生抽样误差的原因是( )。
A.总体中的个体值存在差别 B.总体均数不等于零
C.样本中的个体值存在差别 D.样本均数不等于零
E.样本只包含总体的一部分
3. 均数和标准差的关系是( )。
A.x愈大,s愈大 B.x愈大,s愈小
C.s愈大,x对各变量值的代表性愈好 D.s愈小,x与总体均数的距离愈大
E.s愈小,x对各变量值的代表性愈好
4. 8名某传染病的潜伏期分别为13、15、19、17、12、21、11、180天,平均潜伏期为( )。
A.15 B.16 C.17 D.25 E.26
5. 正态分布曲线下,横轴上,从均数μ到μ+1.96s的面积为( )。
A.95% B.45% C.97.5% D.47.5% E.49.5%
6. 计算抗体滴度的平均滴度习惯上用( )。
A.中位数 B.几何均数 C.百分位数 D.算术均数E.百分位数
7. 表示偏态分布资料变异程度最好用( )。
A.极差 B.四分位间距 C.方差 D.标准差 E.变异系数
8. 在医学和卫生学研究中,下面不是近似正态分布的是( )。
A.正常成人的红细胞数 B.正常成人的身高
C.正常成人的血铅含量 D.正常成人的脉搏数
E.正常人的血压值
9. 某地调查20岁男大学生100名,身高标准差为4.09 cm,体重标准差为4.10 kg,两者的变异程度下列描述哪个正确?( )
A.体重变异度大 B.身高变异度较大
C.两者变异度相同 D.两者变异度不同
E.由于单位不同,两者标准差不能直接比较
10. 区间x±2.58sx的含义是( )。
A.99%的总体均数在此范围内 B.样本均数的99%可信区间
C.99%的样本均数在此范围内 D.总体均数的99%可信区间
E.99%的变量值在此范围内
11. 两个样本均数比较,经t检验,差异有显著性,P值越小,说明( )。
A.两样本均数差别越大 B.两总体差别越大
C.越有理由认为两总体均数不同 D.越有理由认为两样本均数不同
E.两样本和两总体均数都不等
12. 配对t检验的备择假设是( )。
A.μd=0 B.μ=μ0 C.μ≠μ0 D.μ1=μ2 E.μd≠0
13. 单样本t检验的自由度是( )。
A.n1-1 B.n-1 C.n1+n2-1 D.n E.n1+n2-2
14. 假设检验中的第一类错误是( )。
A.拒绝了实际上成立的H0 B.拒绝了实际上不成立的H0
C.拒绝了实际上成立的H1 D.拒绝了实际上不成立的H1
E.不拒绝实际上不成立的H1
15. 成组设计两小样本均数t检验的自由度是( )。
A.n1+n2-1 B.(行数-1)×(列数-1) C.n1+n2-2
D.n E.n-1
二、案例分析题
某年某地随机抽样调查了部分健康成人的红细胞数和血红蛋白量,结果见下表。问题:
(1) 女性的红细胞数和血红蛋白的变异程度哪一个更大?
(2) 计算男性的两项指标的抽样误差。
(3) 该地男女血红蛋白含量是否不同?

(李俊萍王玉平)
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。