



1.应用背景
随着道路交通需求持续快速增长,很多一线城市的出行需求增长已经远远超过道路交通供给增长水平,出行的供需矛盾日益尖锐,分时租赁应运而生。发展分时租赁不仅符合新能源汽车发展规划,而且可以提升车辆使用效率,缓解交通压力,减低环境污染。
本小节介绍了用于估计纯电动汽车分时租赁规模的两种研究方法:相关性分析方法和回归分析方法。并以北京市为例,对北京市目前的分时租赁市场规模进行预测。
2.相关性分析方法
相关性分析方法主要是基于小范围的用户特征调查得到总体用户特征,并且找出相关程度最大的变量以定位分时租赁市场适用人群的特征;成功的分时租赁项目是为了解决上班族日常通勤以及社区居民日常出行的需求。因此需要基于一定的原则选出符合分时租赁目标用户特征的区域,再从区域的居住和工作人口入手,进行分时租赁规模预测。
(1)处理流程
①粗略筛选。基于区域人口普查数据及居民使用非私家车出行的比例,筛选出符合要求的区域。
②精细筛选。具体方法是,依据区域站点周边车辆数目的不同,将该区域的分时租赁预计发展情况分为两类:低速发展(可行,但是增速有限)和高速发展(很有可能增速迅猛),并且调查统计与之最相关的特征值,最后进行描述性统计的汇总。
③根据区域人数,结合一定的估计方法进行需求估计。考虑到获取驾照的年龄段以及人员对新鲜事物的接受程度,统计第二步筛选区域中21~55岁的居民和工作人数,依据一定的市场渗透率估计潜在的会员数目,依据一定的人车比(会员数与分时租赁车辆数的比例)估计需要的车辆数目。
市场渗透率是指参与分时租赁的会员数目占区域总人口的比例。根据行业和地区的不同,市场渗透率的选取也有所不同。人车比是指注册会员人数与分时租赁车辆的比例,即一辆分时租赁车辆服务的会员人数。由于注册会员有活跃与非活跃之分,实际统计往往未剔除非活跃会员人数,因此理论上一辆车服务的会员数要比实际的多。
(2)计算实例
以北京为例,利用相关性分析预测分时租赁的市场。
由于短期内难以调查获取较为精确的区域特征数据,在实际计算时,区域范围以北京16区进行划分。2013年北京16区的户均私人汽车保有情况见表5-2。
表5-2 2013年北京市民用汽车保有情况 (单位:辆)
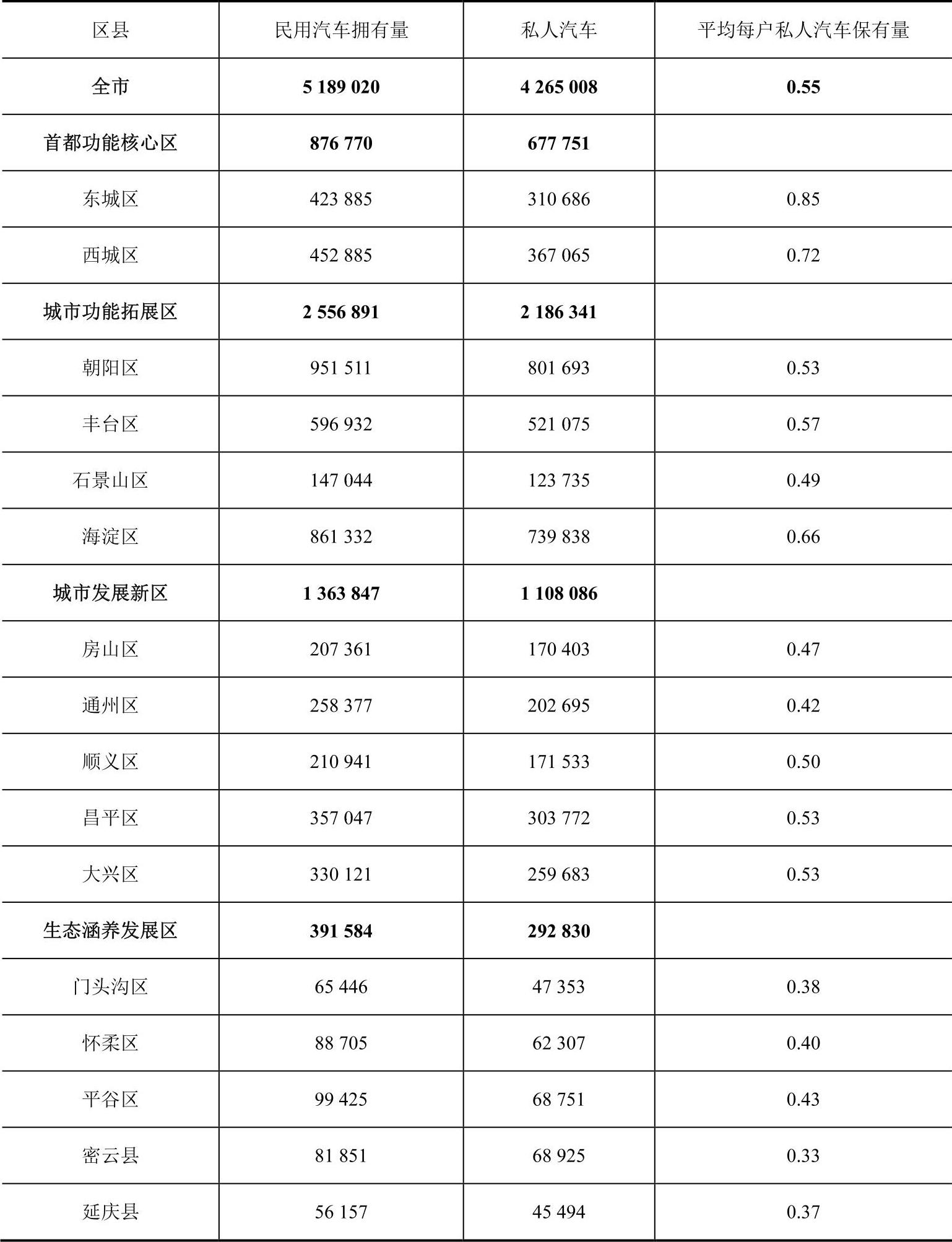
第一步筛选时,由于没有获取到各区的出行结构,暂时采用区域户均私人汽车保有量作为筛选标准。以0.45辆的户均私人汽车保有量作为分界线,将生态涵养发展区的五个区县排除。同时,考虑到通州在北京的规划发展战略地位,将其纳入分时租赁考虑的发展区域中。
在第二步筛选中,由于具体数据缺乏,暂时将所有区都纳入备选区。
在第三步筛选时,统计各区职住人口(在职居住人口),因为采用的是常住人口,已经包含工作人口,所以只需要直接进行21~55岁人口筛选,得到的这部分人数是1181万人。
①人车比和渗透率的选取。人车比和渗透率的选取参照成熟市场的发展经验,表5-3是美国分时租赁不同发展阶段的人车比和渗透率情况。可以看出,北京现阶段分时租赁发展情况与美国初期发展情况一致。
表5-3 美国三个发展阶段的人车比和渗透率
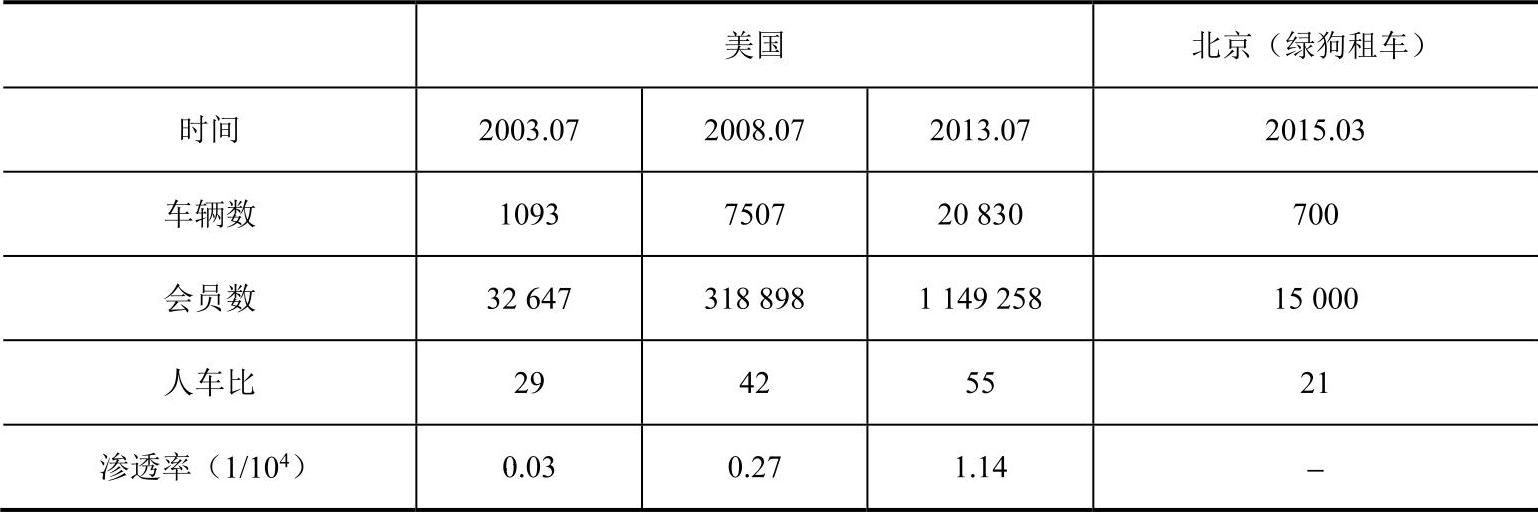
本案例中,人车比采用的是美国2003年、2008年和2013年的人车比数据,分别代表了初期、中期和稳定期三个不同阶段的发展水平。
在选取渗透率时,结合北京的实际情况,现在接入监控平台的分时租赁车辆已经有3000辆左右。此外,在进行人口统计时,采用的数据是北京市常住人口(全年经常在家或在家居住6个月以上,而且经济和生活与本户连成一体的人口),而未考虑短期旅游和商务出差的人口(实住人口),其实这部分人的需求对总需求也是有影响的。综合以上情况,估计有需求时的渗透率为3%~10%。
②会员数和车辆数估算。配合选取的不同的渗透率和人车比,对会员数和车辆数进行估计,如图5-50所示。
从美国的发展情况来看,市场渗透率和人车比随着发展情况由小变大。假设北京未来分时租赁发展变化趋势也与美国变化趋势一致,则图中的红色虚线是较为合理的发展趋势。可见目前发展初期的会员数目有将近35万人,发展到中期有77万人,发展到稳定期有118万人;对应的车辆数目为1.22万辆(初期),1.69万辆(中期),2.15万辆(稳定期)。
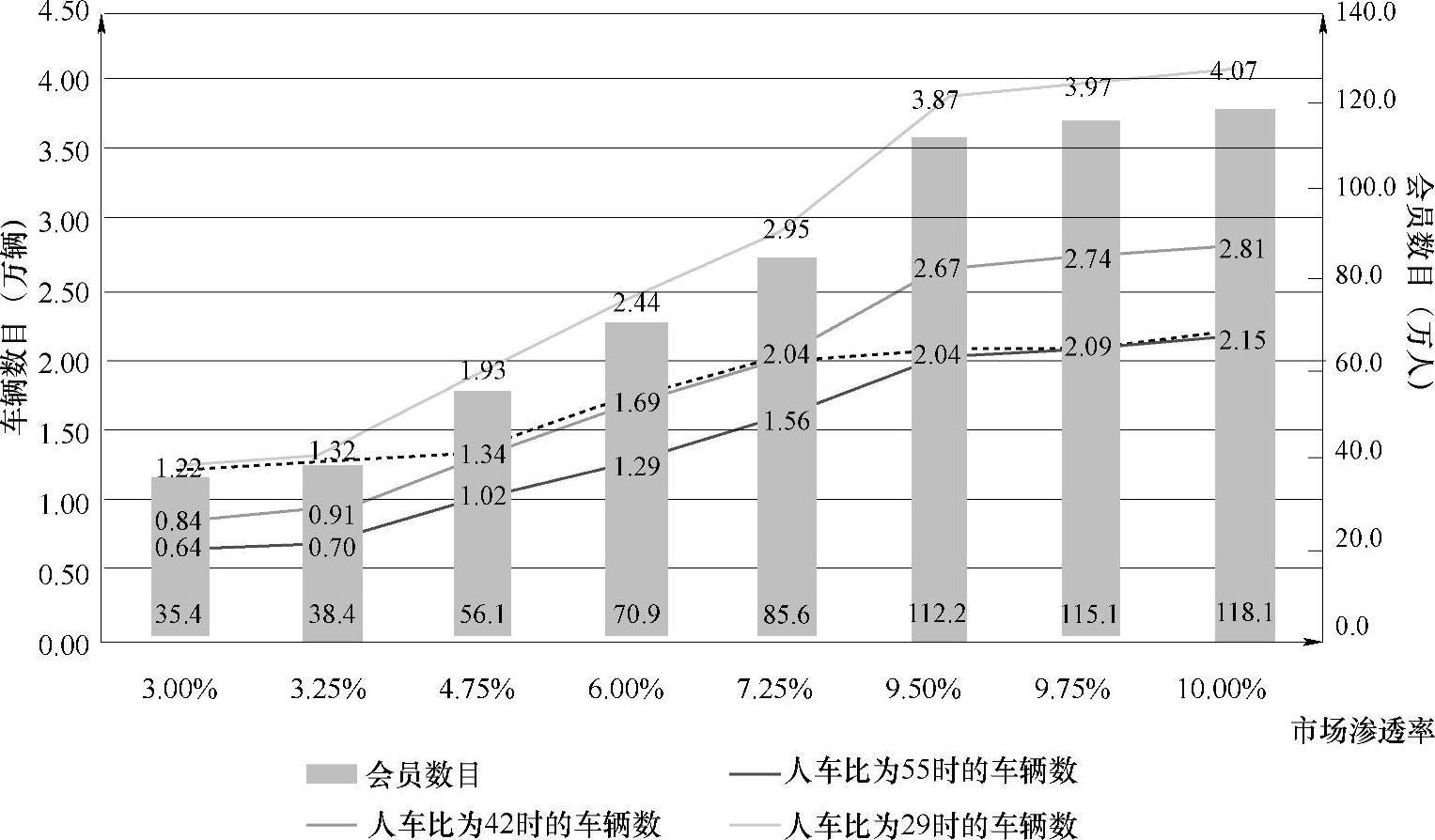
图5-50 会员、车辆数目随渗透率和人车比变化的情况
3.回归分析方法
回归分析方法主要是通过建立回归模型的方式建立租赁市场规模相关变量(如站点用户活跃度、普通人选择分时租赁的概率等)与各类因素之间的数学关系。根据回归数学模型,输入某个特定区域的区域特征,即可输出区域的需求。前期调查的样本容量越大,基于回归分析的预测就越准确。
(1)处理流程
在美国交通研究学术委员会2005年的报告中,试图建立起美国各大城市已有的分时租赁站点周边0.5km半径圆形区域内的分时租赁车辆数目,与该区域内的地理特征、家庭组成、汽车保有情况和交通出行模式(一共13个变量)之间的多元回归模型,并且选出了拟合程度最好的一个多元回归模型如下
LOS=11.305-6.564v+0.00213w (5-35)
式中,LOS为服务级别,表示站点周边0.5km半径圆形区域范围内的分时租赁车辆数目;v为区域内户均车辆数目;w为区域内步行通勤人数。
根据回归模型给定一个站点周边的区域特征,就能计算出站点所需要配置的车辆数目。但是这个回归模型不能对需求人数进行预测,且回归模型的系数也会随着区域的改变而改变。
除此以外,该报告还给出了所有特征与LOS之间的相关系数,见表5-4。
表5-4 区域特征概览
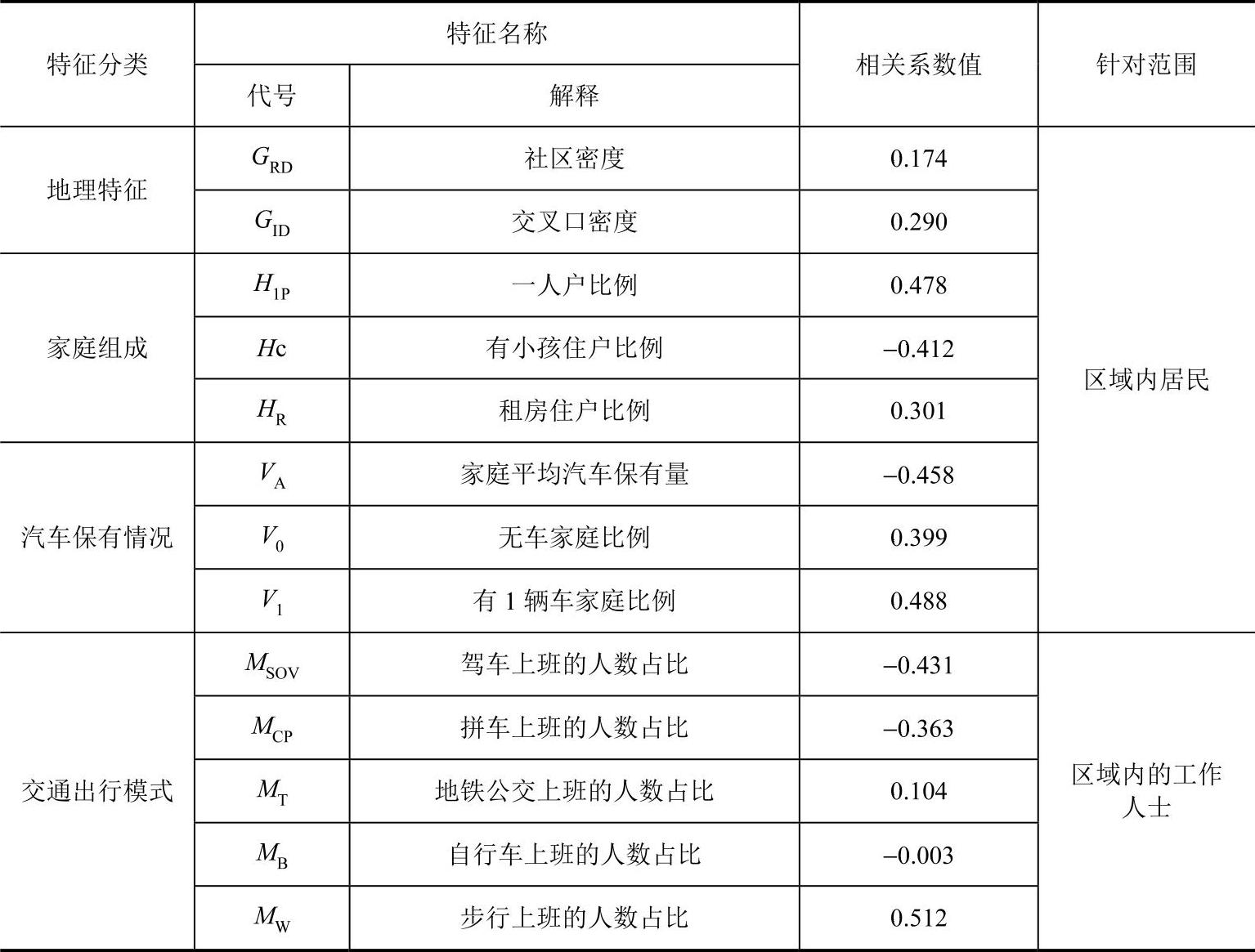
该模型并不是严格的多元线性回归模型,而只是一种无法获取数据下的近似计算。(https://www.xing528.com)
具体计算方法为:

式中,P为站点周边居民的需求人数;N1为地理特征对应的需求人数;N2为家庭组成对应的需求人数;N3为汽车保有情况对应的需求人数;N4为交通出行模式对应的需求人数。
其中:
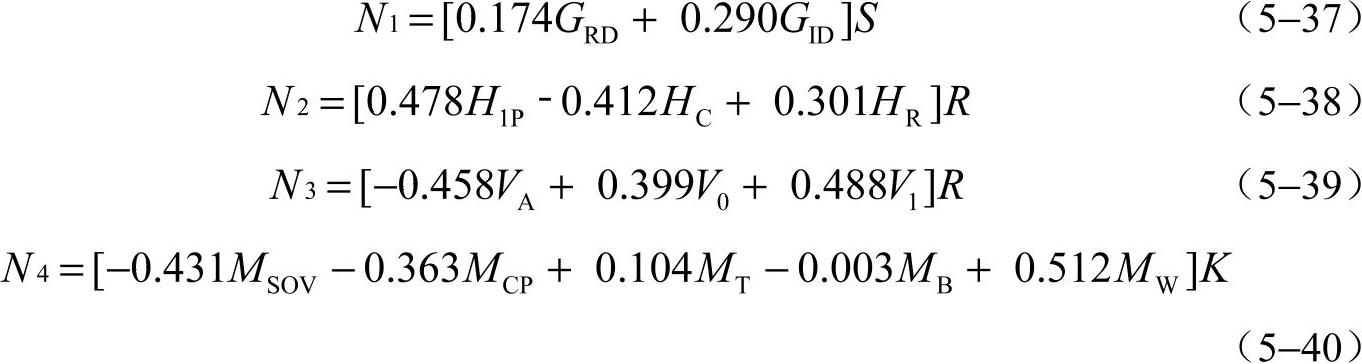
式中,S为站点周边区域面积;R为区域住户数目;K为区域内的工作人数。
考虑一个地区的居民和上班族对于分时租赁的需求,初步拟定估算步骤为:
①区域划分与筛选。结合区域发展情况和特点,选出一定的发展区域(可以依据相关性分析中提到的指导标准),最好能够细化到0.5km半径圆形区域以内。
②统计各个区域各类特征对应的变量,计算区域内存在需求的会员人数。前面论述已经提及,这时的计算并不是依照严格的线性回归,而仅仅是一种近似计算。
③结合第二步筛选出来的会员人数,结合人车比估计所需的车辆数目。人车比的估计参考与前述方法相同,还是采用29、42和55代表初期、中期和稳定期三个不同发展阶段进行估计。
(2)计算实例
同样以北京为实例,利用回归分析去预测分时租赁的市场。
第一步筛选时,与相关性分析的方法一致。
在第二步中,对各区域的各个变量进行了一定的数据收集与估算,如图5-51所示。
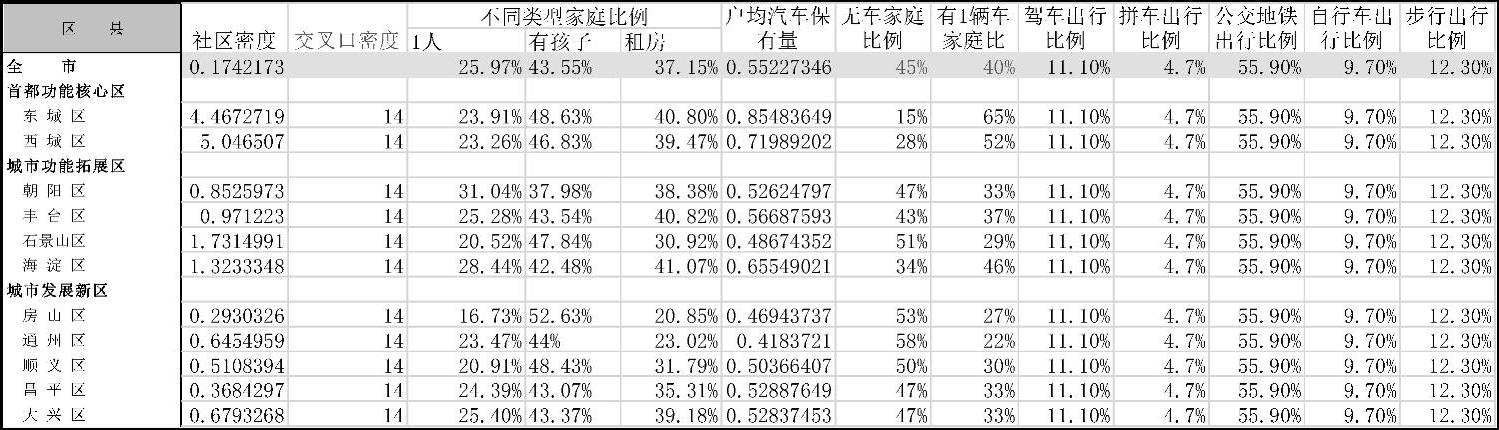
图5-51 北京市各区区域特征数据收集情况概览
结合相关系数的计算方法,计算得到各类需求人数见表5-5。
表5-5 需求人数分类计算及汇总表
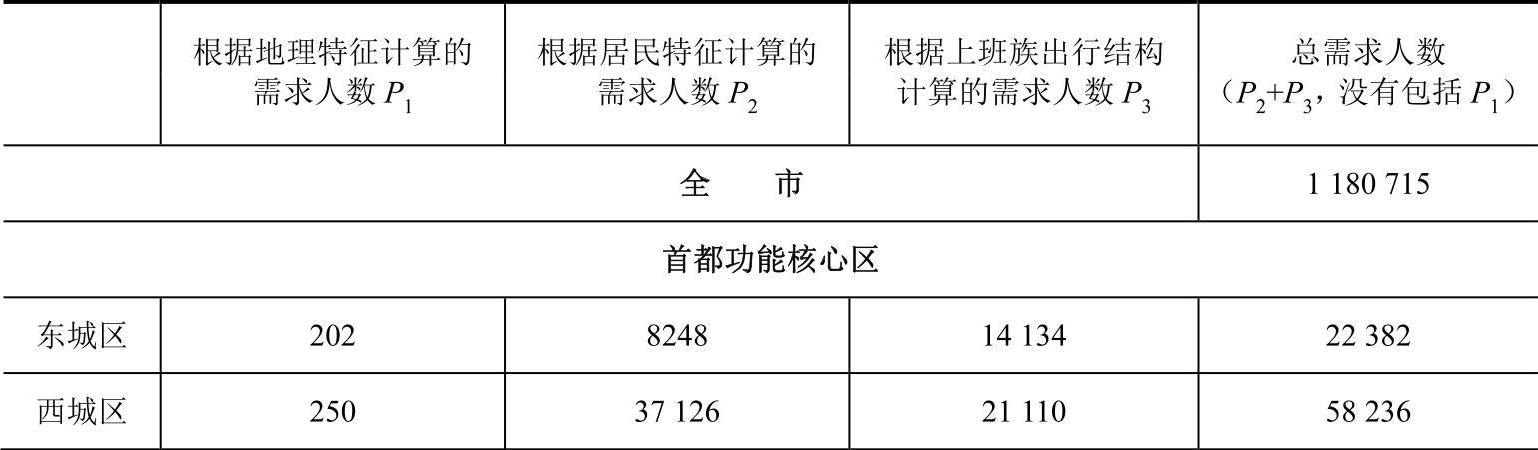
(续)
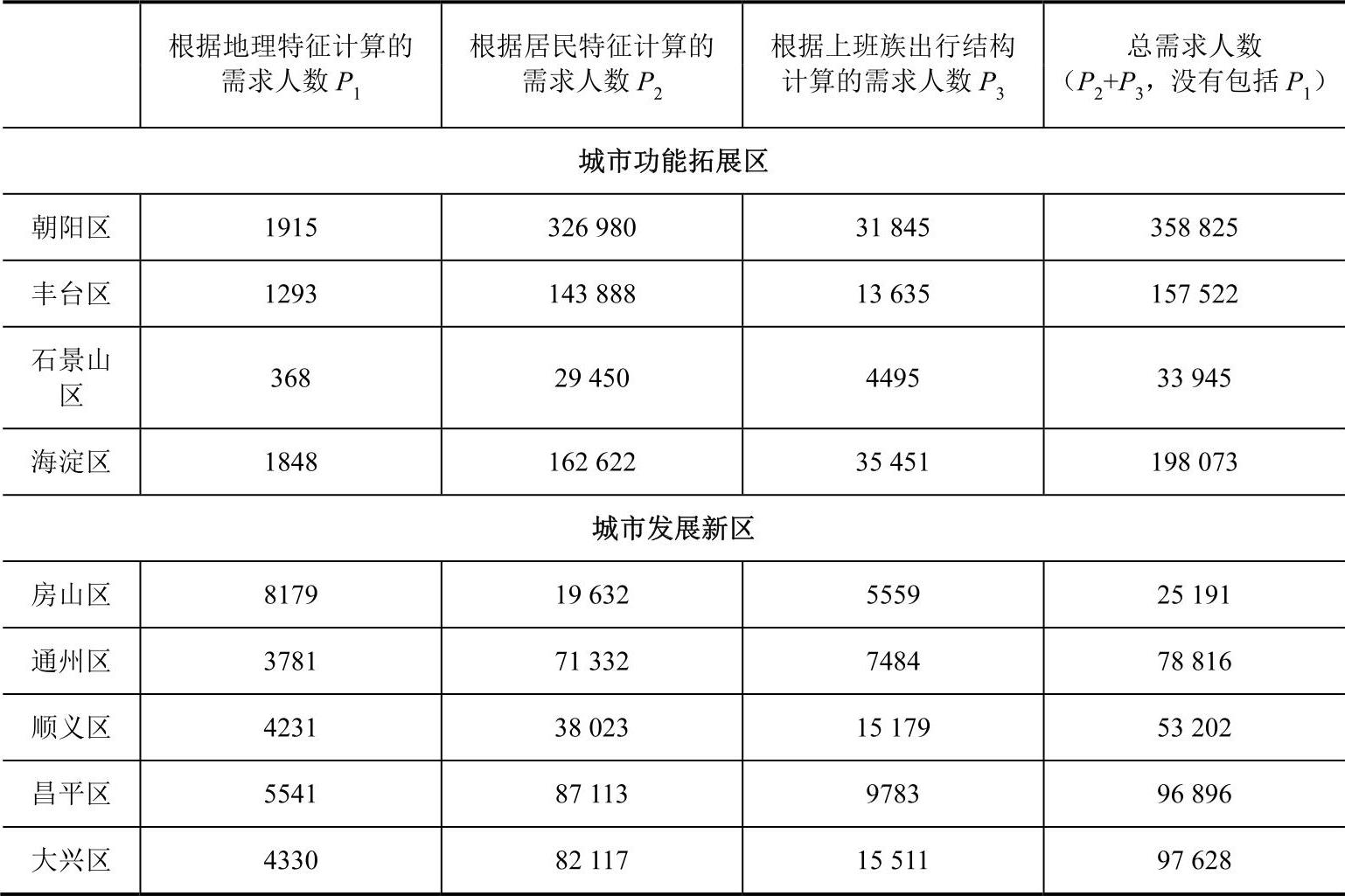
因为地理特征中的交叉口密度数据难以获得,所以在结果汇总中剔除了地理特征对应的需求,计算出当前发展初期,北京的居民和职业人士对分时租赁的需求数量为118万人。
第三步,将该需求人数除以人车比得出车辆需求。不同人车比下的车辆规模如图5-52所示。
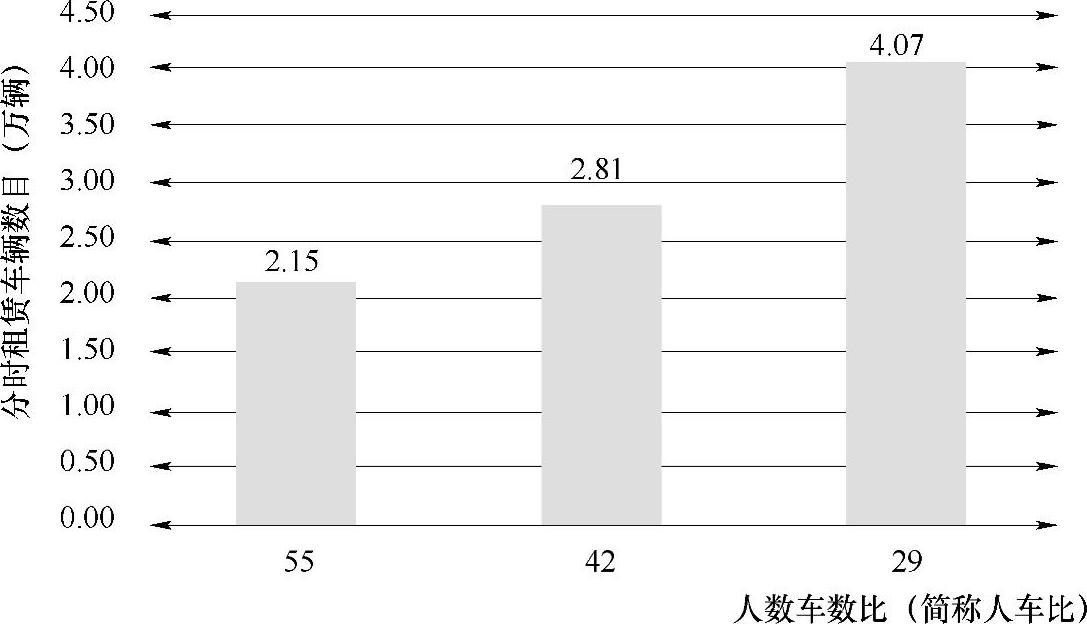
图5-52 依据不同人车比估计的分时租赁车辆数目
如果认为现在是发展初期,118万的会员规模只是初期会员的规模,则应该采用29的人车比计算出来的车辆规模——4.07万辆;而如果认为现在是稳定期,118万会员数目已经是极限,则推荐采用55的人车比计算出来的车辆规模——2.15万辆。
上述计算过程中各个变量对118万需求人数的影响如图5-53所示。
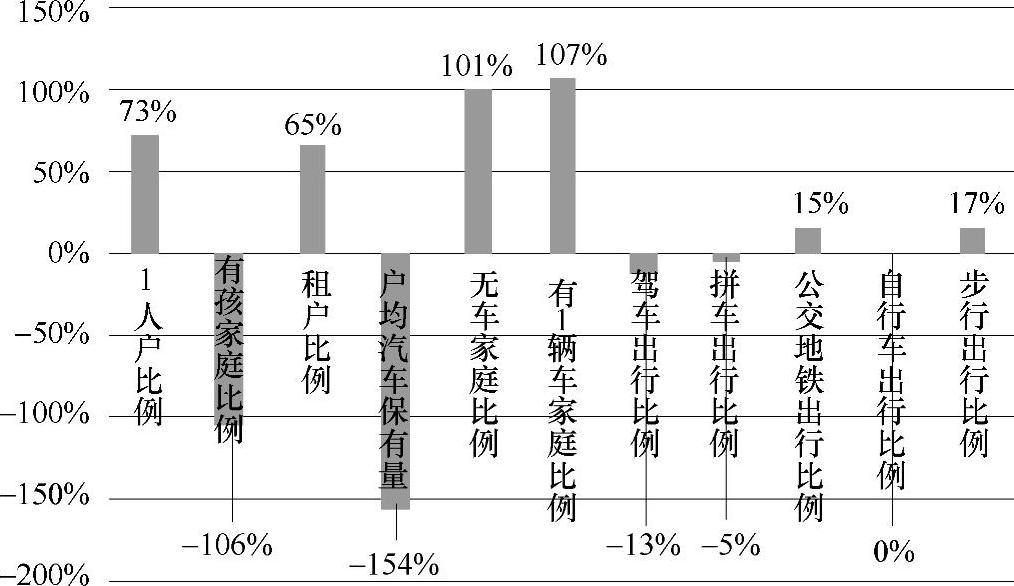
图5-53 各分量对总量的占比
可见,对于给定区域住户数和上班人数的情况下,家庭结构特征与私家车保有特征对于总量的影响最大,而区域内上班人口的通勤特征对总量的影响并不大。该结果可能受区域内统计的上班人数与住户数目之间的数量差异影响,也可能受到相关系数的影响(地铁公交出行比例最大,但是相关系数的值很小)。正相关占比较大的变量按照占比大小排列分别是:有一辆车的家庭比例、无车家庭比例、1人户比例和租户比例;而负相关占比较大的变量按照占比大小排列分别是:户均汽车保有量和有孩家庭比例。
需要注意的是,该计算实例因为其中涉及的变量数值的改变会有改动,更精确的计算需要获取更小范围的区域数据。
4.处理结果对比
根据前述的两种方法,尝试从两种角度对北京市的分时租赁市场规模进行估计。
第一种估计是定性筛选,根据一定的原则将北京分成一个个小区域,将符合要求的区域选出来,再针对该区域的居民和工作人口进行统计得出总的需求人数,结合市场渗透率的概念筛选出潜在的需求人数,再结合人车比得出潜在的车辆数目。这种估计方法比较直观,简单易行,但缺点是需要进行大量的数据调研,区域划分得越小,调研和统计的工作难度会更大。其中一些数据的准确性也有待评估,例如区域内拥有一辆车的家庭的比例等。
第二种估计是定量建模分析,将能够体现区域内分时租赁发展规模的变量(例如每平方千米的分时租赁车辆数目、站点用户活跃度等)作为因变量,然后将站点所在区域内居民的家庭组成、汽车保有情况、区域的地理结构、居民和上班族的出行模式等作为多元自变量,基于大量的调研与统计得到的数据,建立因变量和多元自变量之间的数学模型,在统计学上满足一定的置信度之后,用这个模型去预测在新的区域设置站点后周边的需求。这种估计方法对于前期调研工作量的要求更大,且对于数学模型的处理和建模效果的评估也有较高的要求。
第一种估计找到了1181万总需求人数(作为对比,截至2016年5月,北京市驾驶员数为1012万人),乘以3%~10%的市场渗透率后,我们认为,如果将2015年作为新能源汽车元年,也是分时租赁的初始年,则在未来发展初期阶段会有35~118万的目标用户,按照一个较为平稳的发展态势来看(如图5-48中的虚线所示),则需要1.22~2.15万辆分时租赁车辆。
第二种估计直接找到了118万的目标用户,因为采用的相关系数是美国2004年调研得到的,而当时美国正处于发展初期,因此有理由认为118万人的需求也是比较符合中国当前的发展阶段的。结合人车比信息,估计出分时租赁的车辆需求为2.15~4.07万辆。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。