



语言模型(Language Model)在语音识别和机器翻译等自然语言处理任务中被用于表示文本。如果将文档看作词语的序列,那么语言模型的概率就是预测序列中下一个词语的概率。最简单的语言模型是一元语言模型,即语言中词语的概率分布。在语音识别、机器翻译等任务中,N元语言模型通常使用更长序列来预测词语,在预测时考虑前1N−个词语。最常见的N元语言模型是二元语言模型(即使用前一个词语来预测)和三元语言模型(即使用前两个词语来预测)。Ponte等[31]于1998年首次将语言模型引入信息检索研究,采用查询项似然模型,其主要思路是:给定文档D和查询Q,首先为D建立一个语言模型θD,即文档中词语的概率分布,这样查询Q就可以看作θD的一个随机取样,因此计算过程改为估算概率P(Q|θD)。但是根据人们理解,文档D的得分不应该仅由与查询Q的相关性决定。例如,很多包含垃圾信息的网页,即使与查询Q相关性很高也不应该排在前面,因为这种文档本身没有什么质量。因此,出现了PageRank这种度量网页重要程度的算法,而且在关于语言模型方法的后续研究中,对这种仅考虑文档D和查询Q之间相关性的模型进行了扩展,加入了表示文档自身权重的先验P(θD),它的计算与查询独立。因为可以认为:在基本的语言模型中,文档D的打分是给定查询Q后生成此文档D的概率P(D|θQ)。统计语言模型以一个全新的视角看待检索问题,为相关性排序算法的设计开辟了一个新的方向;此外,语言模型框架简洁,结合对多种检索应用的描述能力以及相关排序算法的有效性,使得这种方法对于基于主题的相关性检索任务是一个很好的选择。
虽然二元语言模型在信息检索中常用来表示两个词语构成的短语,但是信息检索领域重点讨论的是一元语言模型,因为其更加简单,而且被证明作为排序算法的基础非常有效。表示文档的语言模型可以用来通过根据概率分布随机采样的词语来“生成”新的文档。事实上,由于只用了一元模型,生成的文本将会因为没有任何句法结构而非常糟糕,但是与文档主题相关的重要词汇经常出现。直觉上,使用语言模型可以很好地近似作者在撰写文档时构思的主题。文档可以表示成语言模型,查询也可以表示成语言模型,这就导致了三种重要的基于语言模型的检索概率值:基于从文档语言模型生成查询文本的概率;基于由查询产生的语言模型生成文档文本的概率;基于比对上述两种语言模型的结果。
1.查询似然排序
在查询似然检索模型中,根据文档语言模型生成查询Q的概率来对文档进行排序。由于查询的生成概率是指文档在同样主题上与查询的接近程度,因此查询似然检索模型可以被认为是一个主题相关模型。通常,给定查询Q,可以根据贝叶斯法则通过计算概率P(D|Q)来对文档排序,即
式中,P(D)——文档D的先验概率,用于度量文档D与查询Q相关性的先验概率,表示文档自身权重(重要程度);
P(Q)——归一化因子,是查询Q的先验概率,对所有文档都是相同的,因此在用于排序打分时可以忽略;
P(D|Q)——给定文档D后查询Q的似然函数。
根据是否与查询独立,P(D)的计算分为两种:查询独立(Query-Independent)的时间语言模型;查询相关(Query-Dependent)的时间语言模型。
在绝大多数情况下,P(D)都被假设是始终如一的。在这种假设下,概率P(Q|D)可以采用文档D的一元语言模型来计算,即
式中,![]() ——查询Q中词语的个数;
——查询Q中词语的个数;
qi——查询Q中的词语;
P(qi|D)——在文档D的词语分布(Word Distribution)下,词语qi的概率。
为了计算上述概率,就需要估计语言模型概率值。因此,如何估计P(qi|D)是基于语言模型的信息检索的关键。一个直观的计算方式是![]() 。其中,TF(qi,D)表示词语qi在文档D中的出现次数,
。其中,TF(qi,D)表示词语qi在文档D中的出现次数,![]() 表示文档D中的词语数量。对于多项式分布,这是一个极大似然估计,即最大化TF(qi,D)。这个估计方式的主要问题在于,如果查询Q中任意一个词语都没有出现在文档D中,那么P(Q|D)的值为0。此外,在短文本的情况下估计语言模型很困难,这是因为,文档的长度
表示文档D中的词语数量。对于多项式分布,这是一个极大似然估计,即最大化TF(qi,D)。这个估计方式的主要问题在于,如果查询Q中任意一个词语都没有出现在文档D中,那么P(Q|D)的值为0。此外,在短文本的情况下估计语言模型很困难,这是因为,文档的长度![]() 很小,TF(qi,D)不会很大而且通常为1,这直接导致重要的词语很少有机会通过反复使用来脱颖而出。通常采用平滑(Smoothing)技术来避免这种问题以及解决常见的数据稀疏问题。平滑技术降低(或打折)文档中出现的词语的估计概率,并对文档中的未出现词语赋予估计的“剩余”概率。未出现词语的概率通常基于整个文档数据集中词语的出现频率(又称“背景概率”)进行估计:如果P(w|Δ)表示文档数据集Δ的数据集语言模型中词语w的出现概率,那么在上述公式中,文档中未出现词语qi的估计概率为αDP(qi|Δ),其中,αD是控制未出现词语概率的参数。为了保证概率值的和为1,使用(1−αD)P(qi|D)+αDP(qi|Δ)来代替式(9−20)中的P(qi|D)。(https://www.xing528.com)
很小,TF(qi,D)不会很大而且通常为1,这直接导致重要的词语很少有机会通过反复使用来脱颖而出。通常采用平滑(Smoothing)技术来避免这种问题以及解决常见的数据稀疏问题。平滑技术降低(或打折)文档中出现的词语的估计概率,并对文档中的未出现词语赋予估计的“剩余”概率。未出现词语的概率通常基于整个文档数据集中词语的出现频率(又称“背景概率”)进行估计:如果P(w|Δ)表示文档数据集Δ的数据集语言模型中词语w的出现概率,那么在上述公式中,文档中未出现词语qi的估计概率为αDP(qi|Δ),其中,αD是控制未出现词语概率的参数。为了保证概率值的和为1,使用(1−αD)P(qi|D)+αDP(qi|Δ)来代替式(9−20)中的P(qi|D)。(https://www.xing528.com)
αD的不用赋值方式会产生不同的平滑方式。对αD最简单的选择是将其设为常数,即αD=λ。此时,![]() 其中,TF(qi,Δ)表示词语qi在文档数据集Δ中出现的次数,
其中,TF(qi,Δ)表示词语qi在文档数据集Δ中出现的次数,![]() 表示文档数据集中所有词语出现次数总和。这种平滑方式称为Jelinek-Mercer平滑方法。另一种常见的平滑方式是狄利克雷平滑,使用依赖于文档长度的αD=μ/(|D|+μ),其中μ是一个参数,通常根据经验设定μ的值。此时,
表示文档数据集中所有词语出现次数总和。这种平滑方式称为Jelinek-Mercer平滑方法。另一种常见的平滑方式是狄利克雷平滑,使用依赖于文档长度的αD=μ/(|D|+μ),其中μ是一个参数,通常根据经验设定μ的值。此时,
总体而言,查询似然排序直接融合了词语频率,使词语权重的有效性问题更容易理解。通常,基本的查询似然检索模型结合狄利克雷平滑之后,能够达到与BM25模型类似的性能;如果采用基于主题模型的更加复杂的平滑方式,那么查询似然会超过BM25模型。
2.相关性模型
从查询Q中进行估计而产生的语言模型通常称为相关性模型(Relevance Model),用θR表示,因为其表示相关文档覆盖的主题。在这种情况下,查询可以看成相关性模型生成的文本篇幅非常小的样本,相关文档可以看成同一个模型生成的文本篇幅较大的样本。给定关于查询的一些相关样例文档,能够估计相关性模型中的概率,然后使用这个模型来预测新文档的相关性P(D|θR),这个模型也被称为文档似然模型。实际上,P(D|θR)是很难计算的,在获取相关文档的样例方面也存在困难。但是,如果能够从一个查询中估计一个相关性模型,那么就能将这个语言模型和文档语言模型直接进行对比,进而根据文档语言模型和相关性模型的相似程度对文档进行排序。
如果一篇文档的语言模型和相关性模型非常类似,那么这篇文档可能与查询是关于同一个主题的(即内容上是很相近的)。通常,使用信息论和概率论中著名的Kullback-Leibler散度(简称“KL散度”)来衡量这两个语言模型的差异。由于KL散度是非对称的,结果取决于选择哪个语言模型作为“真实分布”。假设真实分布是查询生成的相关性模型θR,近似分布为文档语言模型θD,则负数的KL散度可以表示为
式中,求和公式是对整个词表V中的所有词语进行的;由于公式右边第二项不依赖于文档,所以在排序中可将其忽略。
给定一个简单的极大似然估计P(w|θD),基于查询Q中词语频率(TF(w,Q))和查询Q的词语数量![]() ,文档得分计算方式如下:
,文档得分计算方式如下:
虽然求和公式能够覆盖词表![]() 中的所有词语,但查询中未出现的词语的极大似然估计值为0,而且不会对得分有任何贡献。此外,具有频率p的查询词对文档得分的贡献为p·logP(w|θD),这意味着这个分数和式(9−23)是等价的。换言之,查询似然是检索模型的一种特殊情况,通过比较基于查询的相关性模型和文档语言模型来实现。
中的所有词语,但查询中未出现的词语的极大似然估计值为0,而且不会对得分有任何贡献。此外,具有频率p的查询词对文档得分的贡献为p·logP(w|θD),这意味着这个分数和式(9−23)是等价的。换言之,查询似然是检索模型的一种特殊情况,通过比较基于查询的相关性模型和文档语言模型来实现。
相关性模型的优点在于没有限制使用查询词频率来估计模型参数。如果将查询词看作相关性模型的一种采样,那么基于见过的查询词的新采样概率,就看起来是合理的。给定已经观察到的查询词{q1,q2,…,qn},观察词语w的条件概率,近似估计为P(w|θR)≈P(w|q1,q2,…,qn)。可以根据观察到的词语w和查询词的联合概率来表示条件概率:![]() 。给定一组表示为如 下概率的文档集合
。给定一组表示为如 下概率的文档集合![]() 。同时,假设
。同时,假设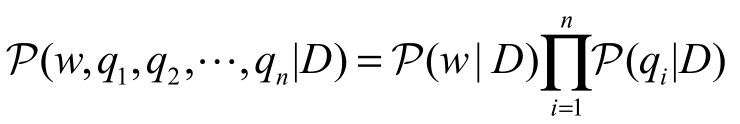 。最终可以得到对联合概率的估计如下:
。最终可以得到对联合概率的估计如下:
式中,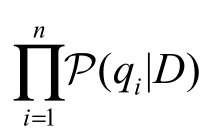 ——文档D的查询似然得分。
——文档D的查询似然得分。
基于相关性模型的排序,实际上需要两轮操作:第一轮,利用查询似然来排序,进而得到相关性模型估计中所需的权值;第二轮,使用KL散度,通过对比相关性模型和文档语言模型来对文档进行排序。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。