



本节中我们将讨论一种最近提出的更为先进的方法,它基于一种特殊的深度结构,用于大规模的文档检索(网络搜索),我们称之为深度结构语义模型或深度语义相似模型(Deep Semantic Similarity Model,DSSM),发表于文献[172]中。在文献[328]中,可以找到该模型的卷积版本,即卷积深度语义相似模型(CDSSM)。
利用现代搜索引擎对网页文档检测主要通过文档关键词与查询关键词匹配的方法进行。然而,一个概念在文档或查询中往往因为用词和语言风格的不同而导致字串匹配的结果不准确。在关键字匹配不奏效的情况下,潜在语义模型能够将查询匹配到语义级别上的相关文档。这些模型把出现在相似语境下的不同术语按照同一语义簇进行分类,用这种方法解决网页文档和查询之间的语言差异。因此,一次查询和某个文档(在低维语义空间分别用两个向量来表示)即使不包含相同的术语,也可能具有很高的相似度。人们提出了诸如概率潜在语义模型(probabilistic latent semantic model)和潜在狄利克雷分配(latent Dirichlet allocation)模型的概率主题模型以解决上述部分语义匹配的难题。然而,这些模型对信息检索效果的改进并没像最初期望的那样显著。主要因为:(1)大多数流行的潜在语义模型都是基于线性映射,无法有效地建模具有复杂语义属性的文档;(2)这些模型通常使用与检索任务的评测标准耦合度不高的目标函数,并在无监督的方式下进行训练。为了改进信息检索中的语义匹配问题,前人通过两方面的研究来扩展上述潜在语义模型。一方面是前面9.1节中提到的基于深度自编码器[165,314]的语义哈希方法。在此方法中,虽然通过深度学习方法可以提取出隐含在查询目标和文档中的分层语义结构,但是模型采用的深度学习方法仍然是一种无监督学习方法,此方法的模型参数优化以重建文档为目的,而不是为了将文档在给定查询的情况下依相关性进行区分。这导致的结果是,深度神经网络并没有比基于关键字匹配的信息检索基线模型好很多。另一方面的研究,称为点击数据(click-through data),利用包含一系列查询和对应的浏览过(点击过)的文档数据来进行语义建模,进而消除查询和网页文档的语言差异[120,124]。这些模型以适合文档排序为目标,用浏览过的数据进行训练。然而,这些基于浏览数据训练出的模型仍然是线性的,因此存在表现力不够的问题。所以要获得比基线明显好的性能,这些模型需要与关键字匹配模型(比如BM25)进行结合才行。
在文献[172]中提到的DSSM方法目的在于通过结合两方面的工作来克服它们的缺点。DSSM用深度神经网络结构来捕捉查询目标和对应文档的复杂语义属性,并将一个文档集合与给定的查询进行排序。简单来说,非线性映射首先将查询和文档映射到一个通用语义空间(common semantic space),然后,计算文档与给定查询在这个语义空间里对应向量之间的余弦相似度。用点击的数据来训练深度神经网络,使得在给定查询条件下,对应点击过的文档的条件似然达到最大。与前面的用无监督方法训练的潜在语义模型不同,DSSM直接为网页文档的排序进行优化,因此可以得到更好的性能。此外,该文献还提出一个新的词哈希(hashing)方法,用于在网页搜索应用中处理大量词汇问题,它将高维字串(high-dimensional term)向量映射到低维N阶字母向量上,而且基本没有信息损失。
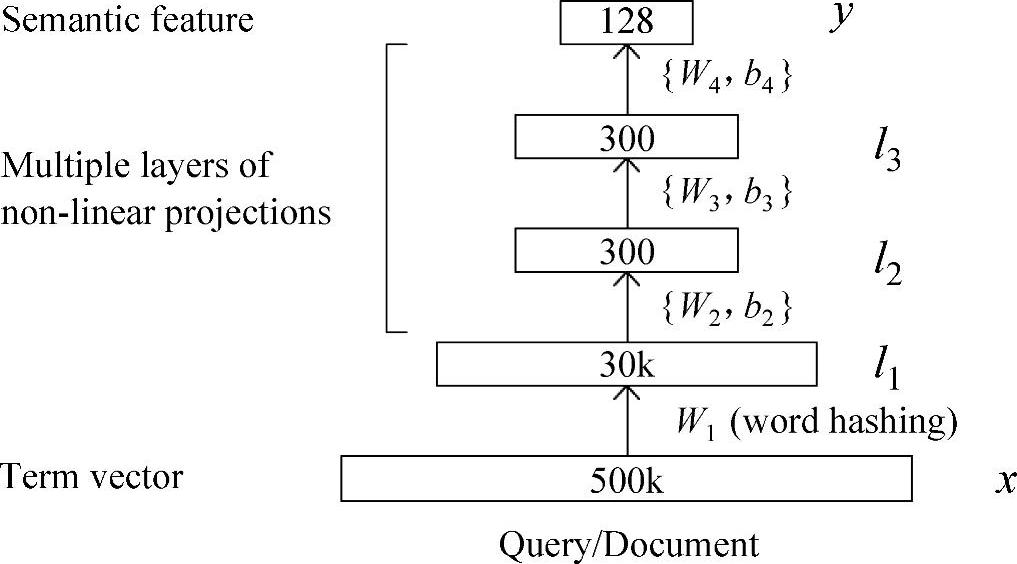
图9.1 在DSSM结构中的DNN部分。在语义空间中用DNN来将查询和文档的高维稀疏文本特征映射到低维密集特征。(参考文献[172],@CIKM)
图中词语翻译对照表

图9.1展示了在DSSM结构中的DNN部分。在语义空间中,用DNN将高维稀疏文本特征映射到低维密集特征上。第一个隐层包含30k个节点,来完成词哈希过程。文本哈希特征通过多个非线性网络层进行映射。这个DNN最后一层的网络激励构成了语义空间的特征。
为了解释图9.1中DNN每层的计算步骤,我们定义x为输入向量,y为输出向量,li,i=1,…,N-1,为中间的隐层,Wi为第i个投影矩阵,bi为第i个偏置向量。我们得到:
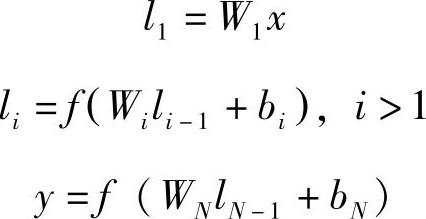
式中,tanh函数用在了输出层和第li个隐层上,li,i=2,…,N-1。
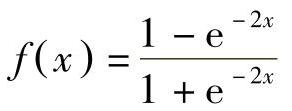
查询Q和文档D的语义相关度分数用如下的余弦距离来计算
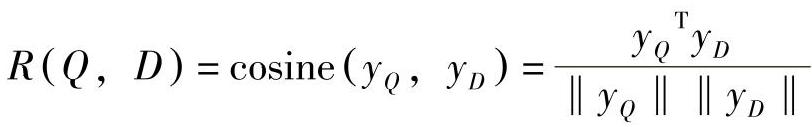
式中,yQ和yD为查询和文档的概念向量。在网络搜索时,给定一个查询,通过文档的语义相关度分数来将文档排序。
图9.1中的DNN权重值Wi和bi的学习是文献[172]的重要贡献。当DNN应用在语音识别中时,标注的训练数据是比较容易找到的,然而在DSSM中,DNN并没有这样明确定义的标注信息。因此,为了用浏览过的网络查询记录作为训练数据来训练DSSM中DNN的权值,损失函数需要以信息检索为中心进行改造,而不是将通常的交叉熵或均方误差作为训练时的目标函数。
浏览过的日志记录包括查询和查询对应的文档。查询通常与浏览过的文档相关度更高,与未浏览过的文档较低,这个弱监督信息可以用来训练DSSM。DSSM中权值矩阵Wi是通过最大化给定查询所对应的已浏览文档的后验概率得到的。(https://www.xing528.com)
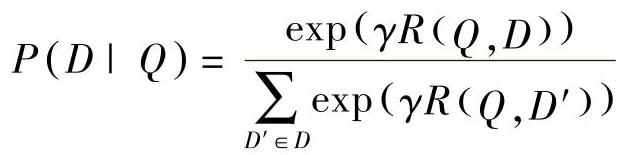
式中,R(Q,D)为查询Q和文档D的语义相关度分数。γ为一个保留(held-out)数据集上经验性的平滑因子,D为待排序候选文档的集合。理论上,D应包含所有可用的文档,正如语音识别中最大互信息的训练中所有负标注都应被考虑到一样[147],但在网络级别上得到D是不可能的。根据语音识别中最小分类错误(MCE)训练中的惯例[52,118,417,418],文献[172]中描述的关于实现DSSM学习方法使用了负标注的子集。换句话说,对于每对查询Q和对应的文档D+,通过D+和4个随机选择的未浏览文档来估计集合D,得到{Dj-;j=1,…,4}。文献[172]指出,用不同的采样策略来选择未标注文档没有很大的差别。
通过上述简化,DSSM的参数以最大化给定查询条件下浏览过的文档的似然概率来估计得到。
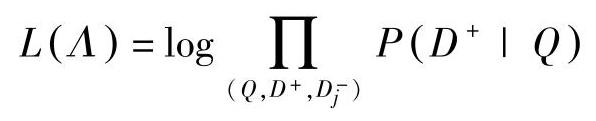
式中,Λ为DSSM中DNN权值{Wi}的参数集合。如图9.2所示,整个DSSM的结构包含了多个DNN。这些DNN共享相同的权值,但输入不同的文档(一个正相关和多个负相关)来训练DSSM的参数。关于DNN中文档和查询权值中近似损失函数梯度计算的细节发表于文献[172]中,这里不再详述。
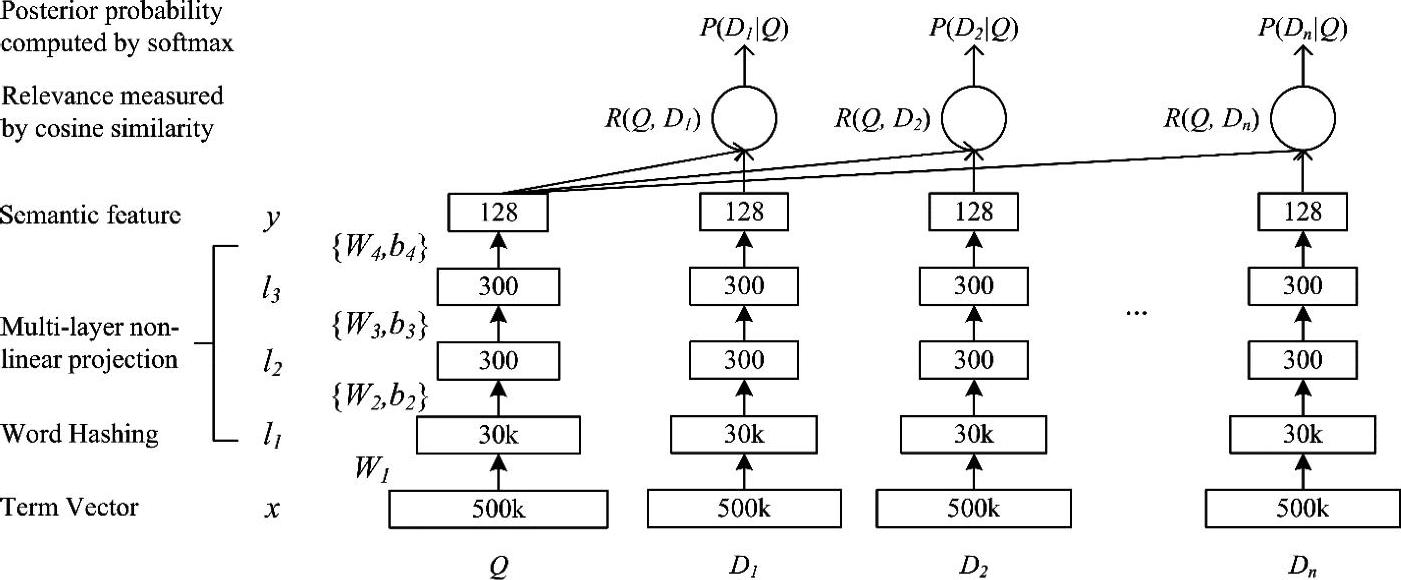
图9.2 文档检索中DSSM的结构(来自文献[170,171])。所有DNN共享权重。n个文档表示用随机的负样本简化训练过程。(参考文献[172],@CIKM)
图中词语翻译对照表
最近,前文所述的DSSM被扩展到了卷积形式,即C-DSSM。它将上下文中语义相似的词映射到卷积结构的上下文特征空间中相近的向量上。由于一个句子的整体语义通常由一些关键词来确定,因此C-DSSM使用一个附加的最大池化(max pooling)层来提取最显著的局部特征,从而形成一个固定长度的全局特征向量。该向量输入到余下的非线性DNN层中,将它映射到共享语义空间(shared semantic space)中的一个点。
图9.3展示了C-DSSM的卷积神经网络的组成成分,其中图示卷积层的窗长为3。C-DSSM的结构与图9.2中DSSM相似,不同点仅在于,C-DSSM用带有局部连接的捆绑权值和附加最大池化层(max pooling layer)的卷积神经网络代替了全连接的DNN。图9.3中的模型部分包含了4个部分:(1)词哈希层,它将词转换到3阶字(letter-tri-gram)向量,这如同DSSM中的方法一样;(2)卷积层,它为每个上下文窗口提取局部上下文特征;(3)最大池化层,它提取并合并局部显著特征来组建全局特征向量;(4)语义层,它代表输入词序列的高级语义信息。
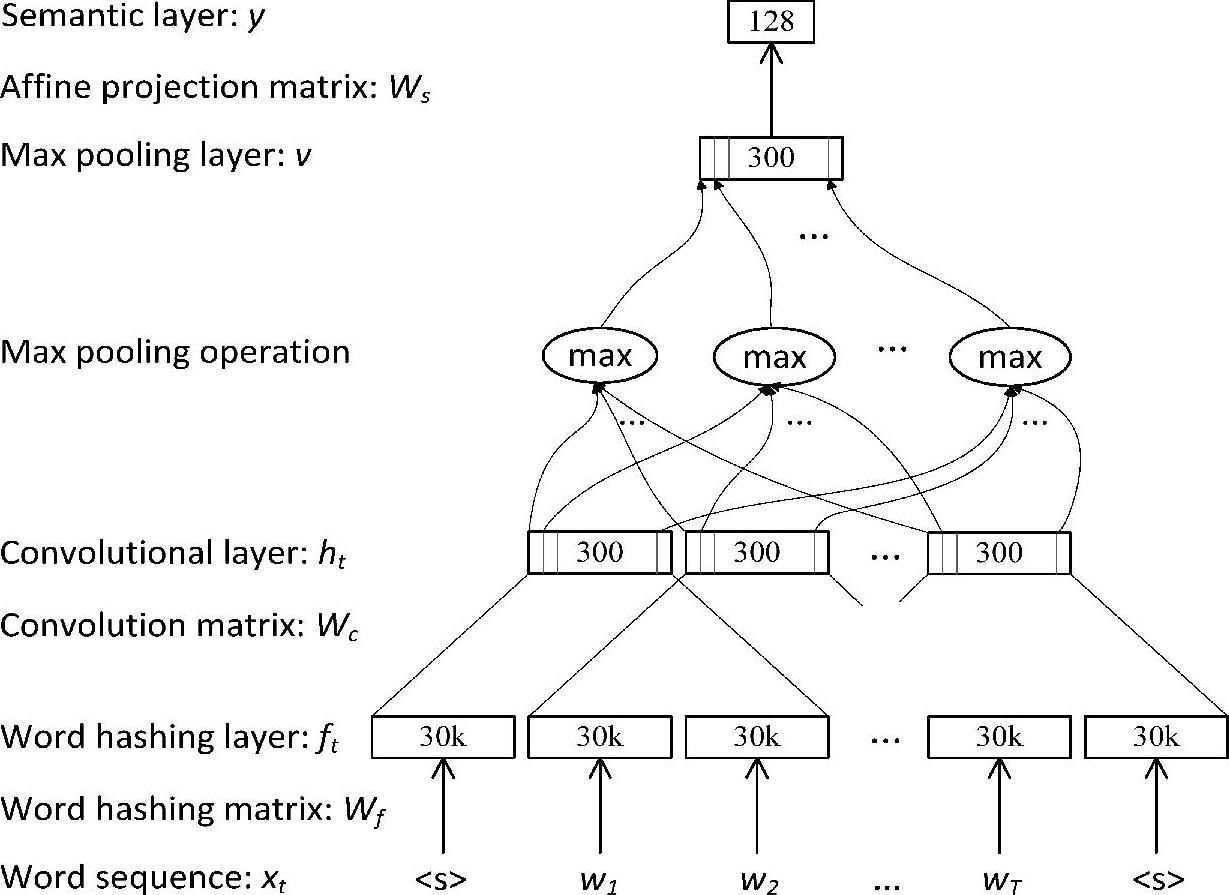
图9.3 C-DSSM中的卷积神经网络组成部分。卷积层的窗长为3。(参考文献[328],@WWW)
图中词语翻译对照表
C-DSSM使用卷积结构的主要动机是,它可以将变长词序列映射到潜在语义空间中的一个低维向量上,这与之前那些模型将查询和文档当作词袋(bag-of-words)的情况是不一样的,查询或文档在C-DSSM中被看作是有上下文结构的词序列。通过使用卷积结构,首先对N阶词(n-gram)级别上的局部上下文信息进行建模。然后,局部显著特征被组合起来用于构建全局特征向量。最后,词序列的高级语义信息被提取出来组成全局向量。和DSSM类似,C-DSSM也在浏览的数据上训练,并使用反向传播算法最大化给定查询条件下的浏览过文档的条件似然值。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。